Using AWS Athena to understand your AWS bills and usage data without setting up a database
At times, you want to quickly query your data in cold storage. This data could be stored in S3, and setting up and loading data into a conventional database like Postgres or Redshift would take too much time. Moreover, you only want these queries once a week, or once a month and keeping your database servers spinning would be expensive.
Amazon Athena is a service that does this for you. You do not need any infrastructure besides S3, so it's truly serverless. You create a schema (table definition), point it to a S3 bucket and you're good to go.
We'll look at using Athena to query AWS's detailed billing and usage data – a perfect use-case for Athena.
What you need before you can proceed
- An AWS account
- Enable your AWS account to export your cost and usage data into a S3 bucket. We'll call this bucket
silota-aws-billing-data. This option is available on the Billing and Cost Management console. - Prepare the bucket for Athena to connect. Athena doesn't like non-data files in the bucket where the data resides. AWS creates a manifest file with metadata everytime it writes to the bucket. We'll create a new folder inside the
silota-aws-billing-databucket calledathenathat only contains the data. - A new IAM user to connect to Athena. We'll call this user
silota-athena- Athena requires a staging bucket to store intermediate results. We'll call this bucket
aws-athena-query-results-silota. - Make sure this IAM account can access both
silota-aws-billing-dataas well asaws-athena-query-results-silota. - We have detailed step-by-step instructions for this step.
- Athena requires a staging bucket to store intermediate results. We'll call this bucket
- To simplify our setup, we only use one region: the
us-west-2region.
At the final step, you'll download the credentials for the new IAM user. The credentials map directly to database credentials you can use to connect:
| Parameter | Value |
|---|---|
| Database host | athena.us-west-2.amazonaws.com |
| Database username | IAM username |
| Database password | Secret Access Key |
| Database name | Access Key ID |
| Database port | 443 |
| S3 staging directory | s3://aws-athena-query-results-silota/ |
Create the Athena database and table
The next step is to create a table that matches the format of the CSV files in the billing S3 bucket. By manually inspecting the CSV files, we find 20 columns.
After a bit of trial and error, we came across some gotchas:
- You need to use the
OpenCSVSerdeplugin to parse the CSV files. - The plugin only supports
gzipfiles, notzipfiles. You'll have to convert the compression format togzipor one of the supported formats. - The plugin claims to support
skip.header.line.countto skip header rows, but this seems to be broken. You'll have to manually rewrite the CSV files without the header. - The data types of all columns are
string, though Athena supports a whole bunch of data types.
You can now run these DDL statements (either via the AWS web console, or using our product) to create the database and the table:
create database if not exists costdb;
create external table if not exists cost (
InvoiceID string,
PayerAccountId string,
LinkedAccountId string,
RecordType string,
RecordId string,
ProductName string,
RateId string,
SubscriptionId string,
PricingPlanId string,
UsageType string,
Operation string,
AvailabilityZone string,
ReservedInstance string,
ItemDescription string,
UsageStartDate string,
UsageEndDate string,
UsageQuantity string,
Rate string,
Cost string,
ResourceId string
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties (
'separatorChar' = ',',
'quoteChar' = '"',
'escapeChar' = '\\'
)
stored as textfile
location 's3://silota-aws-billing-data/athena'
Our first query using Athena
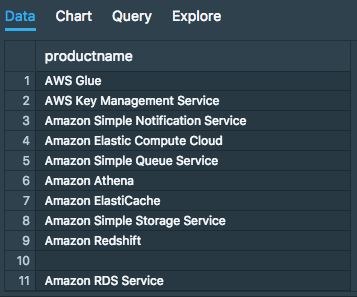
To make sure we're able to query our Athena database, we'll execute the following query to find the number of AWS services we use:
select distinct costdb.cost.productname
from costdb.cost
Cost by AWS service and operation
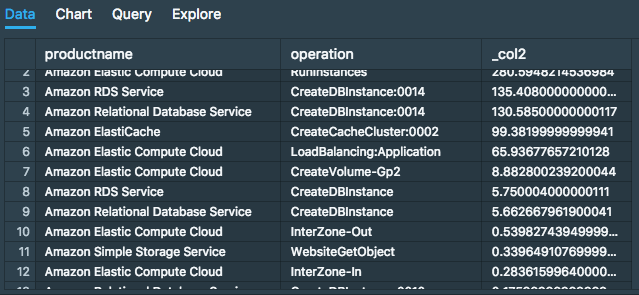
In our gotcha section, we mentioned that each column was a string data type. We'll need to cast the column as one of the supported data types in order to do further operations:
select productname, operation,
sum (cast(cost as double))
from costdb.cost
group by 1, 2
order by 3 desc
Amazon's Cost Explorer
Amazon provides a drag and drop tool called Cost Explorer that comes with a set of prebuilt reports like "Monthly costs by service", "reserved instance usage", etc.
Out of curiosity, we tried to recreate the query above – costs by service and operation. It doesn't seem to be possible.
That's the power of SQL! As long as you have the raw data, you can slice and dice the data to your satisfaction. You can compute Month-over-Month growth rates, build histograms, compute outliers using Z-scores, etc.
Additional considerations
Understanding Athena's pricing model
Athena's pricing model is straightforward – you are charged $5 per TB of data scanned from S3, rounded to the nearest megabyte, with a 10 MB minimum per query.
Reducing Athena's cost
The trick to reduce the cost is to reduce the amount of data scanned. This is possible in three ways:
- Compress your data using gzip or one of the supported formats. If you get a 2:1 compression ratio, you've just reduced the cost by 50%.
- Make use of columnar data format like Apache Parquet. If your query only references two columns, the entire row doesn't have to be scanned resulting in signicant savings.
- Partition the data. You can define one or more partition keys – for example, if your data has a time-based column and a
customer_idcolumn, the amount of data scanned is significantly reduced when your query haswhereclauses for the date and customer columns. The partition keys are setup using table creation.
No spam, ever! Unsubscribe any time. See past emails here.