
Before you can deploy Elasticsearch in production, you will need to understand the data you are trying to index. Understanding the data includes how data flows into the system, and how it is going to be queried. Here are some tips to classify you data and make effective use of Elasticsearch…
Introduction
Elasticsearch is a distributed and scalable search engine based on Apache Lucene. Companies like GitHub and Foursquare use it to power search and analytics in their applications. Being a general purpose indexing engine, elasticsearch will have to be tuned to support your use case. From our experience deploying many Elasticsearch clusters, three specific data workflows become clear.
1. Log Data
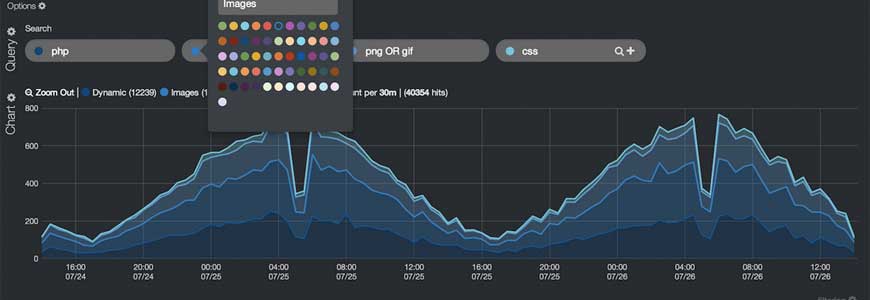
This is most common use case of Elasticsearch. Popularly known as the ELK stack, it combines Elasticsearch, Logstash and Kibana to build a monitoring and search solution for IT operations through open source components.
The general parameters you work with are:
- injest rate: the total number of services in your infrastructure, including webservers, load balancers, database servers and cache servers. You can additionally instrument your application layer to store user events. You’ll have to provision enough capacity to handle 5-10x the load due to burst or cascading effects.
- data retention: determines how you often you archive data to long-term storage to reduce costs.
An interesting metric to think about is the value of log data per megabyte. In most scenarios, only the last few days is hot data and worthwhile to store.
2. Event Data
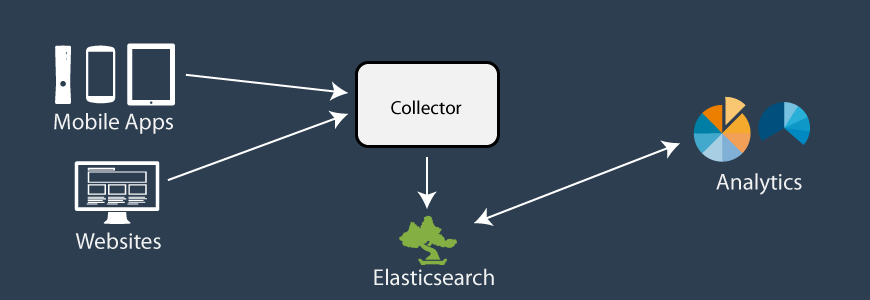
Event data can be from any source: mobile devices, internet of things, and web applications. Event data is unstructured, deeply nested, denormalized and time-stamped. The width (number of fields) of the events can change over time as fields are added and removed over time.
As this type of data is append-only, it is easier to think about storage and computation. The most important queries are aggregates, segmented by a certain dimension and filtered by an additional criteria. You heavily use Elasticsearch’s distributed storage features and additionally a distributed compute layer above it. The compute layer has fast answers to previously asked questions.
3. Entity Data
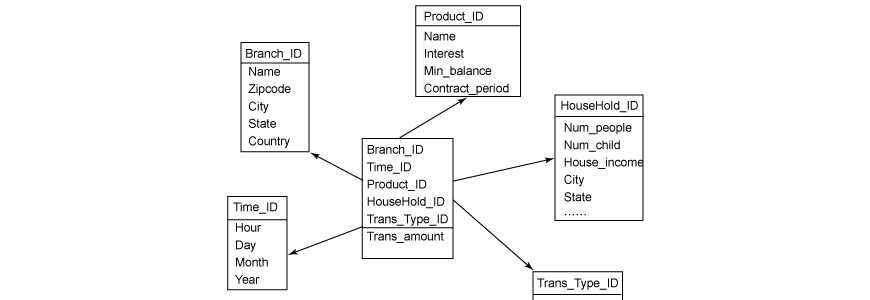
This is data in your database — including customer contact information, transactions, production information, etc. The data follows a strict schema, denormalized and is frequently updated. You’ll want to read our previous post on pulling data from your database to handle this kind of data.
Bottom Line
Understanding the frequency, retention and access patterns of your data will help you in building your Elasticsearch cluster. It’s a mistake to use the same cluster for the different kinds of data — they belong in distinctly tuned clusters.
Photo Credit: Mike Procario